IHPC Summary
This past spring I took the class CSE6220 Intro to High Performance Computing. Though the name says introductory, the content is pretty hard and the workload is heavy. However, the projects were quite fun. Since all projects were implemented with C, pointer manipulation is a must to master in order to achieve a good performance score. Recursion is heavily used too.
List Ranking – OpenMP and CUDA
This is to implemented a list ranking algorithm “Designing Practical Efficient Algorithms for Symmetric Multiprocessors” by Helman & JaJa [1], The paper can be downloaded here.
I won’t go into details, there’s also a very helpful introduction by a fellow classmate, which makes it much easier to understand the concepts. But if you want to implement the algorithm, don’t skip the paper. As a matter of fact, implement it faithfully or your code may end up in a very bad place.
The most interesting part is to implement two versions of the algorithm with OpenMP and CUDA, both of which are fantastic tools for parallel computing. Although my implementations still have a few sequential parts, the final grade shows a ~13x speedup for the OMP version and a whopping 20.9x for the CUDA version. Gustafson’s law rocks!
TeraSort – OpenMPI
As the project name suggests, we are going to sort a huge amount of data, similar to the Hadoop’s Terasort benchmark. It obviously can not be done on a single local machine but with OpenMPI on distributed nodes, Georgia Tech’s PACE. The interesting part of the project is that your score is based on how well your code performs against your peers in the class, a competition. Unfortunately I wasn’t able to join the top 10, only scored 27.5 out of 30, so about 92%.
Cache-Oblivious Sorting
This is an extra credit project, which being means merely correct won’t get any credits, you have to pass a certain performance threshold to get a single credit. The algorithm to implement is the cache-oblivious Funnel Sort, the performance is evaluated by cache misses ratio against Quick Sort. The structure is shown below, the ideal is to divide the data to sort small enough to sit in the cache, and one important part is to make sure the memory layout is continuous.
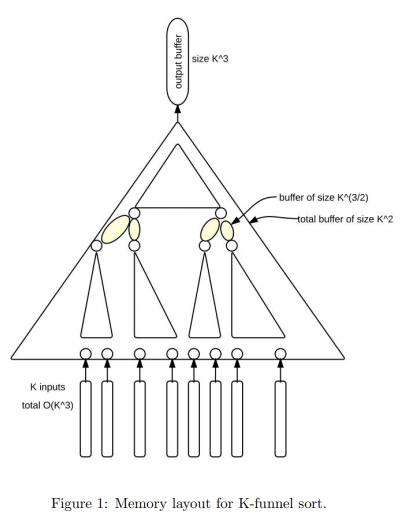
There’s an online introductory lecture by MIT, and I also found the following two papers [2][3] to be very helpful too. My final cache miss ratio was ~ 0.395, which barely passed score 70 out of 100.
Summary
Overall, I found the class to be challenging and I would not recommend taking it as a summer course (which is offered now), but also highly rewarding as many feel the same in the OMScentral.
[1] Helman, David R. and J. JáJá. “Designing Practical Efficient Algorithms for Symmetric Multiprocessors.” ALENEX (1999).
[2] Demaine, Erik D. “Cache-oblivious algorithms and data structures.” Lecture Notes from the EEF Summer School on Massive Data Sets 8, no. 4 (2002): 1-249.
[3] Rønn, Frederik. “Cache-oblivious searching and sorting.” PhD diss., Master’s thesis, University of Copenhagen, 2003.